Blockchain vs Scalability

Scalability is one of the most important aspects of software development. Be it blockchain, or any other technology, it is quite important to ensure that the application we are building is scalable and can adapt to any future requirement. This article is targeted at various software developers, project owners, and architects who have decided to implement blockchain into their tech stack but are concerned about scalability and adaptability
Challenges of Web3
Depending on the current stage of the Software Development Life Cycle, the approach to scalability greatly differs. Before we start with the various possible approaches to scalability, let’s first start by understanding some of the challenges of using Web3 technologies.
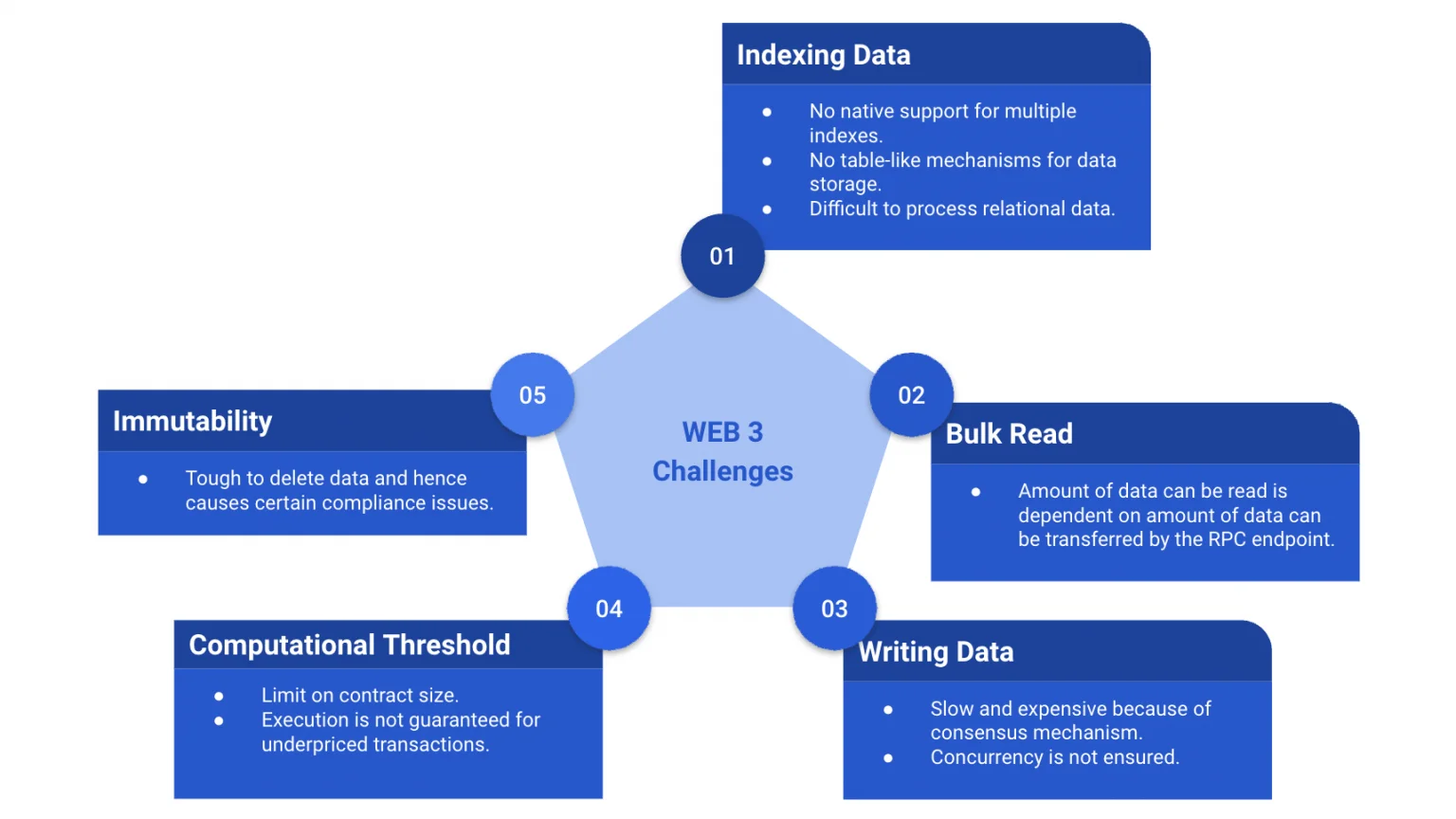
Indexing Data
If we are using a blockchain similar to Ethereum (e.g. Ethereum, Polygon, Avalanche, etc.), it’s important to remember that there is no easy way to have multiple indexes. For example, if we are storing multiple money transfers, in a database first approach it’s very easy to perform operations like sorting by date or grouping by sender/receiver. However, in Solidity there is no native function yet to achieve this and hence something as simple as a filter or sorting of records can be a challenge.
Reading Bulk Data
We use RPC endpoints to connect with a blockchain node and read/write data from it. The downside of this is there is a limit to the amount of data that can be transmitted over the RPC endpoint. Hence, even though the data is securely stored in the blockchain, if we try to fetch the data in bulk, sometimes it’s observed that the RPC is not able to transfer the data, resulting in erroneous output. An example of this is if we try to fetch all the transactions recorded by a certain smart contract. Although we can have functions to return the data in bulk, if there are hundreds of thousands of transactions, probably, the RPC probably won’t be able to deliver the data.
Writing Data
While dealing with Ethereum-based blockchain, aka blockchains that use EVM for smart contract execution, we are required to pay a certain amount of “gas fees” while writing any data onto the blockchain. It’s also important to remember that when we try to write any data into a blockchain, it must go through a complex validation process. Both of these make writing data to a blockchain both expensive and relatively slow.
Another unique challenge that’s often faced by blockchain developers is that if two write operations are performed on the blockchain one-after-another, it’s not always guaranteed that they will be executed in the same order. The order of execution depends upon how much gas fees are paid and what is the total amount of data that must be processed. The blockchain would prefer processing an operation consisting of less data and higher gas fees over any other combination. Hence while designing a system for handling heavy traffic, one must be very cautious to ensure that concurrency is maintained wherever necessary.
Computational Threshold
Since the Spurious Dragon hard fork, there has been an upper limit on the contract size. This means that although theoretically it’s possible to express any algorithm using Solidity, for a sufficiently complex algorithm, you may hit this upper limit. This limit was added to prevent certain DOS attacks and often it’s not recommended to use a separate blockchain where this constraint is not present.
As already discussed, to perform any on-chain computation, the user is expected to pay a fee directly proportional to the amount of computation needed. However, there is one small catch. While validating transactions, a node uses the popular Knapsack Problem approach to decide which transactions must be validated. If a transaction contains a lot of data that requires a lot of computation (for example an algorithm with O(n) complexity), likely, the transaction will likely never be picked up by the validator. This would give rise to a certain degree of uncertainty regarding processing transactions, which is highly unwanted.
Immutability
Although immutability is one of the USPs for using blockchain, under certain conditions, one might want to remove some data. An example of this can be if there is a social media platform that uses blockchain to store various post data, at some point, it might Blockchain vs Scalability 3 want to remove some obscene posts. Such scenarios are especially tricky and often become an entry barrier for various projects.
The following diagram briefly summarizes the main challenges of web3
Solutions to the above challenges
As rightly said, “If there is a will, there is a way”, all the above challenges can be resolved using some novel approaches.

One can argue that some of the above-discussed challenges can be removed by taking certain precautions during smart contract development, for example:
- Indexation Issue: Have different mappings based on the various types of indexation required.
- Bulk Read: Introduce pagination while reading bulk data from the smart contract.
- Writing Data: It is tough to handle this issue solely by smart contract modifications.
- Computational Threshold: Modifying the algorithm to process data in smaller chunks.
- Immutability: It can be resolved to some extent by using upgradable smart contracts, however, it’s still not possible to delete data from the blockchain.
All of these approaches add to the complexity of the smart contract and hence we should explore better ways of optimisation.
Introducing Web 2.5
Arguably one of the best possible approaches towards having a scalable blockchain based application is to leverage the current day Web2 technologies. The Web2 technologies we have at hand are highly stress-tested and it would be a wise decision to harness their power.
But often when people hear Web2 in association with Web3, they are afraid that there is a compromise in traceability or immutability. However, please allow me to prove otherwise.
To ensure that a certain piece of information is not tampered with, it’s not always necessary to store the entire data. Rather we can store just the “hash” of that data, which would act as the fingerprint for that data. If the data is compromised at any point, the hash would change, and one can easily verify the validity of the data by comparing the present hash with the hash stored on the blockchain. At the same time, if any Blockchain vs Scalability 5 intentional update is made, the change in hash can also be recorded on the blockchain which would later signify that the data was updated. Let’s try to understand this better with two examples.
1. A banking system recording transactions:
Let’s take an example of a banking system that records millions of transactions. Storing all these individual transactions on the blockchain as they occur would be quite costly and would also add to the time required for processing a transaction. On the contrary, the banking system, can periodically take a snapshot of the transactions database, generate a hash and store it on the blockchain. So at a certain point in time, if anyone wants to verify if a certain transactional record is genuine or not, he has to just generate the hash of the current snapshot and compare it with the data stored on the blockchain. This would ensure immutability and at the same time, the application can greatly benefit from using a relational database like PostgreSQL for various advanced computations.
2. Machine Learning on Blockchain Data:
A quite lucrative field of technological advancements is to apply advanced ML models on the blockchain data, especially on cryptocurrency transactions, to determine any possible cases of fraud or money laundering. Building a regression model using Solidity is practically impossible. Also to train an ML model you need to run it through various samples of the data. We can’t achieve it without harnessing the power of a database. If we were to build such an application, a feasible approach would be to gradually index the transactions that are to be processed and periodically feed them into the regression model. It is beyond the scope of this article to discuss this in more detail, so in case you are interested, please do let me know in the comments.
Closing Statements
Given the current state of blockchain technologies, there are still many challenges that we come across while building a scalable blockchain application. Every project has its requirements and no one approach fits all. In this article, we explore some common challenges and try to understand how leveraging the power of Web2 can be helpful. Blockchain vs Scalability 6 However, if these don’t cover the challenges you are currently facing, please let me know in the comments, or feel free to reach out to us for an in-depth analysis.
* NOTE: It’s important to note that in this article I have focused mostly on Ethereum based blockchains because of their popularity. Depending on the blockchain framework, the pros and cons vary. I plan to cover the other frameworks separately in my future articles.
Interested in Learning More About x-enabler Book a One-to-One Personalized Call


Leave a comment!